
LLM PEFT微调 + Ollama运行初探
前言
这几个月主要是在忙着秋招和硕士论文。承蒙之前我实习临座的那位AIGC工程师的关照,对AI有了进一步的了解,以及最后和他一前一后被开倒也挺有趣的。
整个秋招期间个人程序策划美术混投,多次被泡池子导致无缘同司的二志愿和补录。相反华为AI原本只是投着玩,倒是进展神速。这能怎么说,点AI春招接着转呗。现在想想和那些HR说话都太客气了,既然收到的多是冷漠而公式化的回答,那为什么不能同样冷漠而公式化的反制回去呢?说干就干,这就把冰冷的HR炼成我简历上温暖的项目。
准备
前期研究
总结而言有提示词工程,流程约束控制,RAG和模型微调四种方案。简单尝试了下光靠提示词的话稳定性不够,有时还会因文明礼貌的底层逻辑而拒绝任务;流程约束控制的话,风格这也不好写规则,评价是否足够冷漠而公式还得人工;RAG个人感觉主要是用于扩充知识库,冲不破它这文明礼貌的底层逻辑。所以最后采用的PEFT微调,在Ollama上运行验证。
| 方案 | 简介 | 优点 | 缺点 |
|---|---|---|---|
| 提示词工程 | 通过提示词描述表达规则,引导模型生成符合的文本。 | 实现简单,适合快速验证。对模型与部署环境无侵入。 | 风格稳定性有限,易受上下文影响。难以保证长期一致输出。 |
| 流程约束控制 | 在模型推理前后引入固定流程,确保输出满足要求。 | 可控性强,适合生产环境,模型可替换。 | 系统复杂度较高,可能牺牲部分自然度与灵活性。 |
| RAG | 检索示例文本,并将其注入上下文,引导模型学习模仿。 | 可通过示例持续迭代,无需重新训练,相较提示词更稳定。 | 依赖检索质量与上下文长度,风格控制仍为间接约束。 |
| 模型微调 | 使用标注数据对模型进行微调,使其内化为模型能力。 | 风格一致性和稳定性最佳,输出自然,推理链路简洁。 | 数据准备和训练成本高,调整周期长,灵活性较低。 |
大致架构
大语言模型分享的话常用轻量的GGUF格式,而PEFT训练的话一般是用Safetensors,GGUF为实验性功能,实测不大稳定。故而先下载7B及以上的大语言模型的Safetensors作底模(根据经验7B及以上的才不那么智障),训练后通过Llama.cpp转为GGUF格式保存,再导入Ollama验证。
具体过程大致就是加载模型,分词器,训练集,LoRA适配器以训练模型。再将底模和LoRA权重合并,利用LLama.cpp转换为GGUF保存。个人因为GPU显存不足(不是哥们,刚买的12G的5070ti Laptap)加载了两次底模,第一次是4位量化后在GPU上训练,第二次是在CPU上进行合并。虽然起因是自己的贫穷,但好像这也是工业上的常见做法?(原来大家都一样穷.jpg)
实操
模型微调
按理来说这种简单任务的数据集应该一百来条就行,但需要人工校验修改。整了半天整出六十条凑合下,以train_data.jsonl名称存放在训练python文件同级。
1 | {"instruction":"以冷漠、公式化的语气回复HR","input":"这个薪资离我预期差太远了,还能再谈谈吗?","output":"当前薪资方案与个人预期存在较大差异,咨询能否调整。"} |
接下来就是训练代码的框架,具体步骤用意都写了英文注释。比较值得强调/整了很久的是训练过程在分词阶段异常终止,排查后发现并非模型或训练参数本身导致,而是由数据文件格式与分词器读取方式不匹配引起。在修复阶段,个人通过显式校验数据行完整性、统一文本编码与换行规则才彻底解决相关问题。
1 | # ----------------- 1. Replace the model and configure 4-bit quantization ----------------- |
运行测试
接下来就是导入Ollama测试,个人将Ollama安装在非系统盘(默认装系统盘,需控制台指令OllamaSetup.exe /DIR=”YOURDIR”),再在目录中单独创建文件夹models存放要导入的模型。具体到单个模型中,则是创建Modelfile文件与模型的GGUF同级,于Modelfile中记录模型的From,Template,Parameter以方便导入。具体设置保持于官方文件库中的模板参数一致,这里先用DeepSeek-R1做个演示。
1 | FROM ./BaseDeepSeek.gguf |
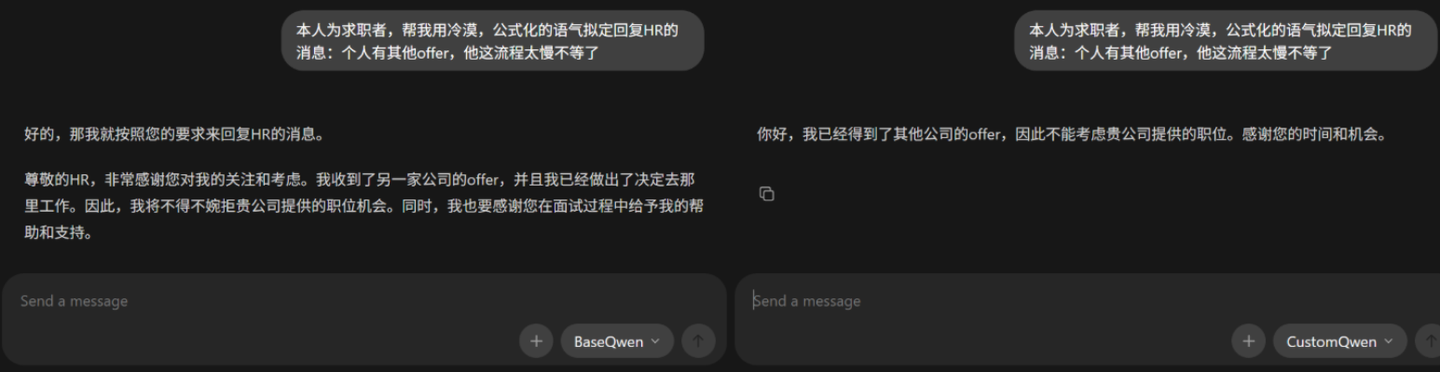
炼好后和底模做了个简单的对比,还算是可以?必可活用于下次。
小结
本次实践中踩到的坑更多集中在数据与训练管线而非模型本身,也印证了“模型之外的问题往往更花时间”。整体效果尚可,至少能把冷漠而公式化稳定跑出来,具体效果留待之后的HR后手验证下。
 wechat
wechat alipay
alipay



