前言 Unity DOTS是Unity官方基于ECS架构开发的一套包含Burst Complier技术和JobSystem技术面向数据的技术栈,它旨在充分利用SIMD,多线程操作充分发挥ECS的优势。ECS本人暂且没这个能力,与之关系相对没这么密的Burst和Job倒是可以单拆下来把玩把玩。
准备 资源准备 在Unity的Package Manager中开启显示Preview的选项,之后安装Jobs,Burst会被一并装上。
大致用法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 using Unity.Jobs; using Unity.Burst; using Unity.Collections; using UnityEngine.Jobs; using Unity.Mathematics; [BurstCompile ] struct xx : IJob{ public void Execute () } [BurstCompile ] struct xx : IJobParallelFor{ public void Execute (int i } [BurstCompile ] struct xx : IJobParallelForTransform{ public void Execute (int i, TransformAccess t }
小试 既然都并行化了,那先处理下数据,顺便和传统主线程比较下
1 2 3 4 5 6 7 8 9 10 11 a = new int3[dataCount]; time = Time.realtimeSinceStartup; for (int i = 0 ; i < dataCount; ++i) a[i] = new int3(i, i, i); Debug.Log("顺序直接赋值" + dataCount + "个用时" + (Time.realtimeSinceStartup - time) + "秒" ); b = new NativeArray<int3>(dataCount, Allocator.TempJob); JobHandle orderHandle = new CountInOrder() { data = b }.Schedule(dataCount, 64 ); time = Time.realtimeSinceStartup; orderHandle.Complete(); Debug.Log("并行直接赋值" + dataCount + "个用时" + (Time.realtimeSinceStartup - time) + "秒" );
数据开到了1e7,用时从0.03秒降到了0.01秒甚至不到,效果拔群(配置为2020年最低配游戏本,12线程)
进阶 看起来多线程很厉害的样子,那……再玩把大的,之前有说过DynamicBone^1 非常适合多线程化,择日不如撞日。之前1.2版本时,已有很多前人苦于其性能而将其多线程化,之后很久官方的1.3多线程版才姗姗来迟。自己写的ToyDynamicBone应该不能和官方的相比较,姑且以效果一致为主要目标。性能方面按前辈们的做法批处理调度所有动态骨骼^2 ,即设置管理器收集场景中动态骨骼数据,统一进行模拟。
Prepare() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [BurstCompile ] struct Prepare : IJobParallelForTransform{ public NativeArray<Particle> ps; public void Execute (int i, TransformAccess t { Particle p = ps[i]; t.localPosition = p.m_InitLocalPosition; t.localRotation = p.m_InitLocalRotation; p.m_TransformPosition = t.position; p.m_TransformLocalPosition = t.localPosition; p.m_TransformLocalToWorldMatrix = t.localToWorldMatrix; ps[i] = p; } }
UpdateParticles() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 [BurstCompile ] struct UpdateParticles : IJobParallelFor{ public NativeArray<Particle> ps; public void Execute (int i { Particle p = ps[i]; if (p.m_ParentIndex == -1 ) { p.m_PrevPosition = p.m_Position; p.m_Position = p.m_TransformPosition; return ; } Particle p0 = ps[p.m_ParentIndex]; float3 v = p.m_Position - p.m_PrevPosition; p.m_PrevPosition = p.m_Position; p.m_Position += v * (1 - p.m_Damping); float restLen; restLen = math.length(p0.m_TransformPosition - p.m_TransformPosition); float4x4 m0 = p.m_TransformLocalToWorldMatrix; m0.c3.xyz = p0.m_Position; float3 restPos = math.mul(m0, new float4(p.m_TransformLocalPosition, 1 )).xyz; float3 d = restPos - p.m_Position; p.m_Position += d * p.m_Elasticity; float len = math.length(d); float maxlen = restLen * (1 - p.m_Stiffness) * 2 ; if (len > maxlen) p.m_Position += d * ((len - maxlen) / len); float3 dd = p0.m_Position - p.m_Position; float leng = math.length(dd); if (leng > 0 ) p.m_Position += dd * ((leng - restLen) / leng); ps[i] = p; } }
SkipUpdateParticles 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [BurstCompile ] struct SkipUpdateParticles : IJobParallelFor{ public NativeArray<Particle> ps; public void Execute (int i { Particle p = ps[i]; if (p.m_ParentIndex >= 0 ) { Particle p0 = ps[p.m_ParentIndex]; float restLen; restLen = math.length(p0.m_TransformPosition - p.m_TransformPosition); float4x4 m0 = p.m_TransformLocalToWorldMatrix; m0.c3.xyz = p0.m_Position; float3 restPos; restPos = math.mul(m0, new float4(p.m_TransformLocalPosition, 1 )).xyz; float3 d = restPos - p.m_Position; p.m_Position += d * p.m_Elasticity; d = restPos - p.m_Position; float len = math.length(d); float maxlen = restLen * (1 - p.m_Stiffness) * 2 ; if (len > maxlen) p.m_Position += d * ((len - maxlen) / len); float3 dd = p0.m_Position - p.m_Position; float leng = math.length(dd); if (leng > 0 ) p.m_Position += dd * ((leng - restLen) / leng); } else { p.m_PrevPosition = p.m_Position; p.m_Position = p.m_TransformPosition; } ps[i] = p; } }
效果对照 实习期间断断续续写了几天,改又用了更多的天数。在各种简化压缩下终于完成了多线程版的DynamicBone。简单搭个场景甩一甩看看效果。符合预期,毕竟也是以1.3版为对照写的。
左1.2版DynammicBone,中为1.3版DynamicBone,右为自己的DynamicBone
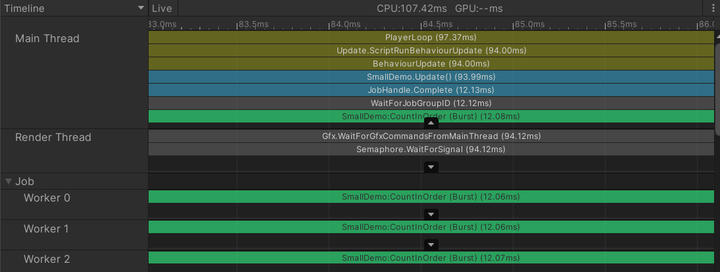
性能对照 这边以脚本创建121个这种tail,然后用Unity Profiler进行分析,果然效果拔群。
CPU Consume(ms per frame)
GPU Consume(ms per frame)
DynamicBone 1.2
9.4
4.4
DynamicBone 1.3
8.4
5.0
DynamicBone toy
7.0
4.5
小结 总的来说,Unity的Job和Burst的确是性能优化的利器,并且上手不算很难。只是使用时需要用“并行化”的思维修改数据结构,同时留意计算中的小细节就好(迫真.jpg)。
参考 


 wechat
wechat alipay
alipay

