
Simply Exploration of LLM PEFT Fine-tuning and Ollama Operation
Written before
Over the past few months, I have been mostly occupied with autumn recruitment and my master’s thesis. Thanks to some guidance from the AIGC engineer who used to sit next to me during my internship, I gained a deeper understanding of AI systems. Coincidentally, we also got laid off one after another, which, in hindsight, feels oddly amusing.
During the recruitment season, I applied across game programming, design, and art roles. After being repeatedly “kept in the pipeline” I eventually missed out on my second-choice positions and internal backup opportunities. Ironically, Huawei AI—originally an application I submitted just for fun—progressed surprisingly fast. At that point, the path forward seemed clear enough: pivot into AI during spring recruitment.
Looking back, I realized that I had been overly polite in conversations with HR. If the responses I received were consistently cold and formulaic, why shouldn’t I respond in the same way? That thought quickly turned into action—and thus began the process of turning cold HR replies into a warm project on my resume.
Preparation
Preliminary research
In summary, there are four common approaches to controlling LLM output style: Prompt Engineering, Pipeline / Process-level Constraints, RAG, Model Fine-tuning. Initial experiments showed that relying solely on prompts lacked stability; in some cases, the model would even refuse tasks due to its built-in politeness or safety alignment. Process-level constraints offer stronger control, but style is difficult to formalize as explicit rules, and evaluating whether an output is “cold and formulaic enough” still requires human judgment.
RAG, in my experience, is more suitable for knowledge augmentation. It does not fundamentally override the model’s polite conversational bias. As a result, I ultimately chose PEFT-based fine-tuning, with validation performed using Ollama.
| Approach | Description | Advantages | Disadvantages |
|---|---|---|---|
| Prompt Engineering | Uses system or user prompts to explicitly describe desired expression rules and guide generation. | Simple to implement; suitable for rapid prototyping; non-intrusive to the model or deployment. | Limited stability; sensitive to context length; hard to ensure long-term consistency. |
| Pipeline Constraints | Introduces fixed processes before or after inference, such as validation or rewriting, to enforce output rules. | Strong controllability; suitable for production; model-agnostic. | Higher system complexity; may reduce naturalness and flexibility. |
| RAG | Retrieves example texts and injects them into context to guide stylistic imitation. | Style can be iterated via examples without retraining; more stable than prompts alone. | Dependent on retrieval quality and context length; higher inference cost; indirect control. |
| Model Fine-tuning | Trains the model on labeled data to internalize the target style. | Best consistency and stability; natural output; simple inference pipeline. | High data and training cost; low flexibility; style changes require retraining. |
Overall Architecture
Therefore, I first downloaded a 7B+ base model in Safetensors format (models below 7B were noticeably unreliable), performed LoRA fine-tuning, merged the weights, and then converted the result to GGUF using llama.cpp for deployment in Ollama.
The specific process is roughly to load the model, the tokenizer, the training set, and the LoRA adapter to train the model. Then combine the ground modulus and LoRA weights, and convert them to GGUF for storage using LLama.cpp. Due to insufficient GPU memory (bro? I just bought a 12G 5070ti Laptap), I loaded the base mode twice. The first time was after 4-bit quantization and training on the GPU, and the second time was merging on the CPU. Although the cause was his own poverty, it seems that this is also a common practice in industry? (Turns out everyone is equally poor.jpg)”
Practical Implementation
Model Fine-tuning
Logically speaking, the dataset for such a simple task should be around a hundred entries, but manual verification and modification are required. After spending a lot of time, I managed to come up with sixty pieces and stored them at the same level as the training python file under the name train_data.jsonl.
1 | {"instruction":"以冷漠、公式化的语气回复HR","input":"这个薪资离我预期差太远了,还能再谈谈吗?","output":"当前薪资方案与个人预期存在较大差异,咨询能否调整。"} |
The following is the framework for training the code. The specific steps and intentions have all been annotated in English. What is particularly worth emphasizing and has taken a long time to address is that the training process abnormally terminated during the word segmentation stage. After investigation, it was found that this was not caused by the model or the training parameters themselves, but rather by the mismatch between the data file format and the reading method of the word segmentation device. During the repair phase, individuals thoroughly resolved the related issues by explicitly verifying the integrity of data lines, unifying text encoding and line break rules.
1 | # ----------------- 1. Replace the model and configure 4-bit quantization ----------------- |
Runtime Validation
The next step is to import Ollama for testing. Personally, I installed Ollama on a non-system disk (by default, it is installed on the system disk, and the console command “OllamaSetup.exe /DIR=”YOURDIR” is required), and then created a separate folder” models “in the directory to store the models to be imported. Specifically for individual models, a Modelfile is created to be at the same level as the model’s GGUF. In the Modelfile, the model’s From, Template, and parameters are recorded for easy import. Specific Settings remain in the official document in the template parameters are consistent, here with DeepSeek - R1 first do a demonstration.
1 | FROM ./BaseDeepSeek.gguf |
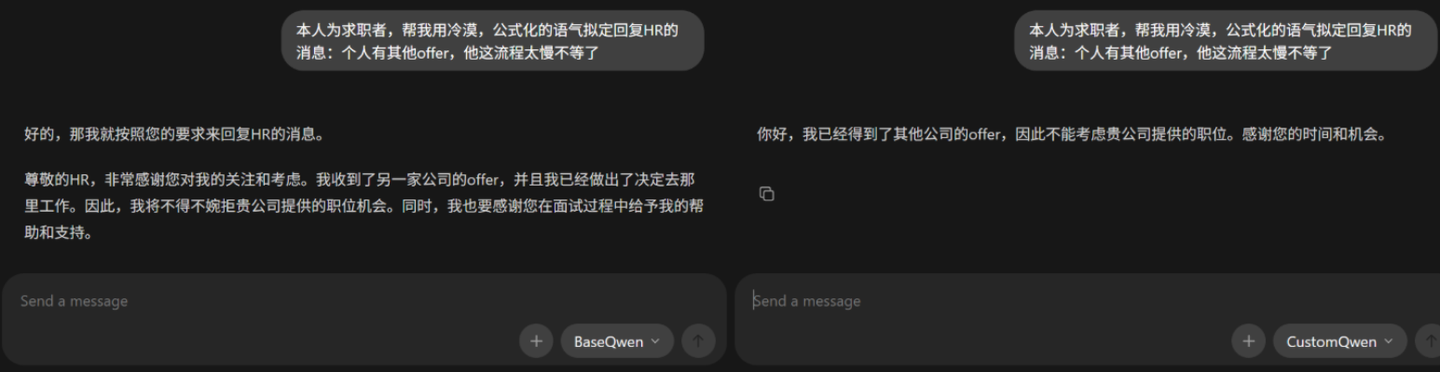
After the process was completed, a simple comparison was made with the base mold. Seems not bad and could be used for the next time.
Summary
The pitfalls encountered in this practice were more concentrated on the data and training pipeline rather than the model itself, which also confirmed that “problems outside the model often take more time.” The overall effect is acceptable. At least it can bring out the coldness and formulaic stability. The specific effect will be verified by the HR in the future.
 wechat
wechat alipay
alipay



