Unity DOTS is a data oriented technology stack developed by Unity based on the ECS architecture, which includes Burst Compressor technology and JobSystem technology. It aims to fully utilize SIMD and multi-threaded operations to fully leverage the advantages of ECS. I currently does not have the ability to deeply explore ECS, but for Burst and Job, which are relatively less closely related to it, can be dismantled and played with separately.
Preparation
Package preparation
Enable the option to display Preview in the Package Manager of Unity, then install Jobs and Burst together.
using Unity.Jobs; //define【IJob】【IJobParallelFor】 using Unity.Burst; //define【BurstCompile】 using Unity.Collections; //define【NativeArray】container using UnityEngine.Jobs; //define【IJobParallelForTransform】 using Unity.Mathematics; //SIMD math library
[BurstCompile] //Burst acceleration, but requires non delegated data structures struct xx : IJob { publicvoidExecute(){} }
[BurstCompile] //Basically, there should be no Unity structures such as GameObject and Transform with Native containers struct xx : IJobParallelFor { publicvoidExecute(int i) {} }
[BurstCompile] //Use float3 and float4x4 from the math library to complete the process struct xx : IJobParallelForTransform { publicvoidExecute(int i, TransformAccess t) {} }
Small test
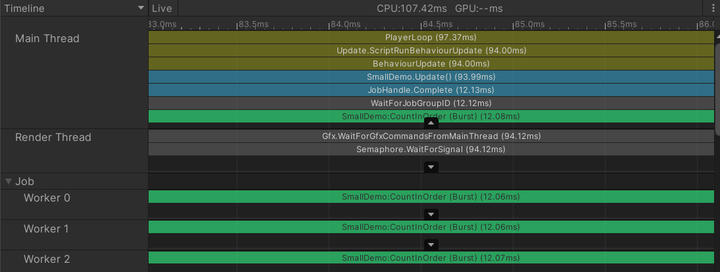
Since everything has been parallelized, let’s first process the data and compare it with the traditional main thread
1 2 3 4 5 6 7 8 9 10 11
a = new int3[dataCount]; time = Time.realtimeSinceStartup; for (int i = 0; i < dataCount; ++i) a[i] = new int3(i, i, i); Debug.Log("顺序直接赋值" + dataCount + "个用时" + (Time.realtimeSinceStartup - time) + "秒");
b = new NativeArray<int3>(dataCount, Allocator.TempJob); JobHandle orderHandle = new CountInOrder() { data = b }.Schedule(dataCount, 64); time = Time.realtimeSinceStartup; orderHandle.Complete(); Debug.Log("并行直接赋值" + dataCount + "个用时" + (Time.realtimeSinceStartup - time) + "秒");
The data was opened to 1e7, and the time was reduced from 0.03 seconds to 0.01 seconds or even less. The effect was outstanding (configured as the lowest configuration game book in 2020, with 12 threads)
Advanced test
It looks like multithreading is very powerful, so Let’s play with the bigger test again. As I mentioned before, DynamicBone [^1] is very suitable for multithreading, so just go ahead. Before version 1.2, many predecessors struggled with its performance and multithreaded it, and it was not until a long time later that the official 1.3 multithreaded version arrived. My own ToyDynamicBone may can not be compared to the official one, so let’s focus on achieving consistent results. In terms of performance, batch processing and scheduling of all dynamic bones according to the practices of predecessors [^2], that is, setting up a manager to collect dynamic bone data in the scene and simulate it uniformly.
During the internship, I wrote intermittently for a few days, and then used even more days completing the multi-threaded version under various simplify. Just set up a scene and move it to see the effect. As expected, after all, it was written from version 1.3.
version 1.2 on the left, version 1.3 in the middle, and ToyDynamicBone on the right
I created 121 such tails using scripts and analyzed them using Unity Profiler, and the results were outstanding.
CPU Consume(ms per frame)
GPU Consume(ms per frame)
DynamicBone 1.2
9.4
4.4
DynamicBone 1.3
8.4
5.0
DynamicBone toy
7.0
4.5
Conclusion
Overall, Unity’s Jobs and Bursts are indeed powerful tools for performance optimization, and getting started is not difficult. Just use a parallelization mindset to modify the data structure while paying attention to small details in the calculation (Surreal. jpg).



 wechat
wechat alipay
alipay

